
From ripples to waves
Perceptron 부터 Self-Attention 까지 요약 본문
- Perceptron: 선형 모델 → XOR 문제 해결 불가.
- MLP: 은닉층 추가로 비선형 문제 해결 → 시계열 데이터 처리 불가.
- RNN: 시계열 데이터 처리 가능 → 장기 의존성 문제.
- LSTM: RNN 개선 → 병렬 처리 불가.
- Attention Mechanism: RNN/LSTM 강화 → 순차적 처리 문제는 여전.
- Self-Attention (Transformer): 병렬 처리와 입력 간 관계 학습의 완성형 → 현재 딥러닝 모델의 중심.
1. Perceptron (1958)
단순한 선형 모델
- 등장배경: 초기 인공지능 연구에서 "컴퓨터가 사람처럼 학습할 수 있을까?"라는 질문에서 시작.
- 구조: 입력(feature)들을 가중치(weight)와 곱한 후, 결과를 합산하고, 활성화 함수를 통해 이진 출력(예: 0 또는 1)을 생성.
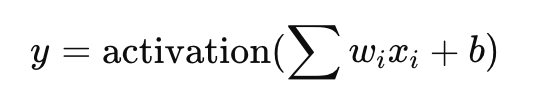
- 한계: 선형 모델이기 때문에 XOR 문제와 같은 비선형 데이터를 분류할 수 없음.
2. MLP (Multi-Layer Perceptron)
다층 구조로 비선형 문제 해결
- 등장배경: Perceptron의 한계를 극복하기 위해 은닉층(hidden layer)을 추가. (차수를 높여보자!)
- 구조:
- 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성.
- 각 층에서 활성화 함수(예: ReLU, Sigmoid)를 사용하여 비선형성을 추가.
- 장점: XOR 문제와 같은 비선형 데이터도 학습 가능.
- 한계:
- 은닉층이 깊어질수록 기울기 소실(Gradient Vanishing) 문제가 발생.
- 시계열 데이터나 공간적 데이터에서 입력의 순서나 구조를 학습하지 못함.
3. RNN (Recurrent Neural Network)
시계열 데이터 처리를 위한 재귀적 구조
- 등장배경: MLP는 입력 간의 순서(시간적 종속성)를 고려하지 못했기 때문에, 시계열 데이터(예: 텍스트, 음성, 주식 데이터 등) 처리가 어려웠음. (데이터 길이와 크기가 정해져있는 static image와 달리)
- 구조:
- 이전 상태(hidden state)를 현재 입력과 함께 계산하여, 시간적 의존성을 학습.
- 한계: 긴 시퀀스를 처리할 때 장기 의존성 문제와 기울기 소실 문제가 여전히 발생.
4. LSTM (Long Short-Term Memory)
장기 의존성 문제 해결
- 등장배경: RNN이 긴 시퀀스 학습에 실패하는 문제를 해결하기 위해 등장.
- 구조:
- 기존 Hidden state 뿐 아니라, 장기기억을 담당하는 Cell state를 도입
- 게이트 메커니즘(Forget, Input, Output Gates)을 도입하여 중요한 정보는 기억하고, 불필요한 정보는 제거.
- 장점: 장기 의존성 문제 완화, RNN보다 더 긴 시퀀스 학습 가능.
- 한계:
- 병렬 처리 불가능 → 학습 속도와 효율성 저하.
5. Attention Mechanism (2014)
모든 입력 간의 중요도 학습
- 등장배경: RNN과 LSTM에서도 긴 시퀀스에서 핵심 정보를 놓칠 가능성이 있었음.
- 핵심 아이디어:
- 시퀀스의 각 요소 간 관계(중요도)를 계산하여, 모델이 중요한 부분에 더 집중하게 함.
- 예: 번역 모델에서 특정 단어가 다른 단어와 얼마나 관련이 있는지 학습.
- 장점:
- RNN/LSTM의 성능 강화.
- 입력 간의 종속성 학습.
6. Self-Attention (Transformer, 2017)
모든 입력 간의 관계를 병렬로 학습
- 등장배경: Attention 메커니즘의 강점을 극대화하고, RNN/LSTM의 순차 처리 문제를 해결하기 위해 등장.
- 구조:
- Self-Attention: 시퀀스 내 모든 단어 간의 관계를 동등하게 계산.
- Multi-Head Attention: 여러 Attention을 동시에 수행하여 다양한 관계 학습.
- Positional Encoding: 입력 시퀀스의 순서 정보를 추가.
- 장점:
- 병렬 처리 가능 → 학습 속도 대폭 향상.
- 장기 의존성 문제 해결.
- RNN/LSTM을 완전히 대체할 수 있음.
- 한계:
- 계산량이 많음 → 최적화를 위한 하드웨어 자원 필요.
'AI, Robot' 카테고리의 다른 글
| 랭체인 활용해서 간단한 RAG 구현해보기 (0) | 2025.01.13 |
|---|---|
| GPT-3의 1750억 파라미터는 대체 무슨 의미일까? (0) | 2024.12.31 |
| Sovereign AI(소버린 AI)의 중요성 (3) | 2024.12.23 |
| 한국은 Vertical AI에서 기회를 잡을수도? (0) | 2024.12.19 |
| AI 연구 히스토리 (1950s - 2020s) (5) | 2024.12.15 |
'AI, Robot' Related Articles
more

